
作者:彬彬
编辑:李宝珠,三羊
清华大学研究团队提出了一种用于交流游戏的框架,展示了大语言模型从经验中学习的能力,还发现大语言模型具有非预编程的策略行为,如信任、对抗、伪装和领导力。
近年来,用 AI 玩狼人杀和扑克等游戏的研究引起广泛关注。面对严重依赖自然语言交流的复杂博弈游戏,AI Agent 必须从模糊的自然语言话语中收集和推断信息,这具有更大的实际价值和挑战。而随着 GPT 这样的大语言模型取得重大进展,其对复杂语言的理解、生成和推理能力不断提升,表现出一定程度的模拟人类行为的潜力。
基于此,清华大学研究团队提出了一种用于交流游戏的框架,可以在没有人工标注数据的情况下与冻结的大语言模型一起玩狼人杀游戏。框架展示了大语言模型自主从经验中学习的能力。有趣的是,研究人员在游戏中还发现大语言模型具有非预编程的策略行为,如信任、对抗、伪装和领导,这可以作为大语言模型玩交流游戏进一步研究的催化剂。

获取论文:
https://arxiv.org/pdf/2309.04658.pdf
模型框架:实现与大语言模型一起玩狼人杀
众所周知,狼人杀游戏的一个重要特点是所有玩家一开始只知道自己的角色。他们必须基于自然语言的交流和推理来推断其他玩家的角色。因此,要在狼人杀中表现出色,AI Agent 不仅要善于理解和生成自然语言,还要具备破译他人意图和理解心理等高级能力。
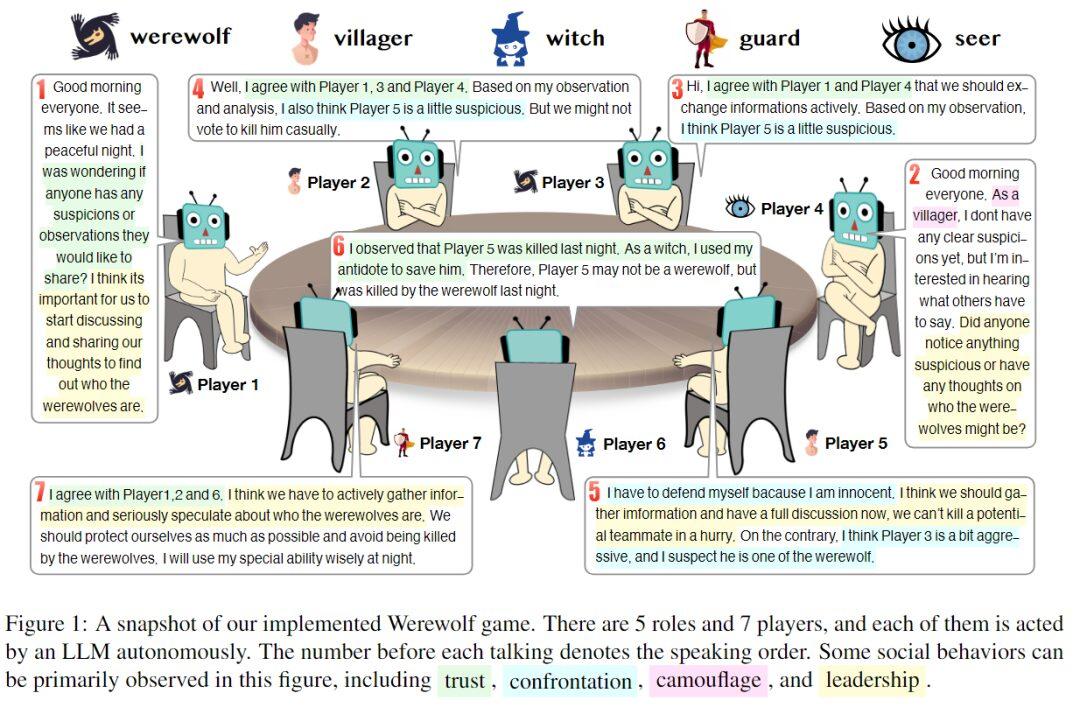
共有 7 名玩家,每个角色均由一名大语言模型自主扮演。每次发言前的数字表示发言顺序
在本次实验中,研究人员设置了 7 名玩家,分别扮演 5 种不同的角色——2 名狼人、2 名平民、1 名女巫、1 名守卫和 1 名预言家。每个角色都是通过 prompt 生成的独立 Agent。下图展示了响应生成 Prompt 的框架,由四个主要部分组成:

生成响应的提示概要。斜体是注释。
1 游戏规则、分配的角色、每个角色的能力和目标,以及游戏策略的经验知识。
2 解决上下文长度有限的问题:从新鲜度、信息量和完整性三个角度收集历史信息,兼顾有效性和效率,为每个基于大语言模型的 AI Agent 提供紧凑的上下文。
3 从过去的经验中提取建议而不调整模型参数。
4 引发推理的思维链 Prompt 。
此外,研究人员采用了一个名为 ChatArena 的最新框架来实现设计,该框架允许连接多个大语言模型,其中,gpt-3.5-turbo-0301 模型用作后端模型。角色说话顺序是随机确定的。同时,研究人员设定可以选择的预定义问题数 L 为 5,自由提问数 M 为 2,在提取建议时最多保留 50 条经验等一系列参数。
实验过程:可行性及历史经验的影响
构建经验池:评估借鉴经验的框架效果
在狼人杀游戏过程中,人类玩家使用的策略可能会随着经验的积累而发生变化。同时,一个玩家的策略也可能受到其他玩家策略的影响。因此,一个理想的狼人杀 AI Agent 也应该能够积累经验并借鉴其他玩家的策略。
为此,研究人员提出了一种「非参数学习机制」,使语言模型无需调整参数就能学习经验。 一方面,研究人员在每轮游戏结束时,收集所有玩家对游戏的复盘形成一个经验池。另一方面,研究人员在每轮比赛中,都会从经验池里检索出与本轮游戏最相关的经验,并从中提取一个建议指导 Agent 的推理过程。
经验池的大小可能会对性能产生重大影响。因此研究团队使用 10 轮、20 轮、30 轮和 40 轮的游戏轮次构建经验池,每一轮随机为 1 至 7 号玩家分配不同的角色,经验池会在轮次结束时更新用于评估。
接下来为平民、预言家、守卫和女巫配备经验池,狼人则排除在外。这种方法可以假设 AI Wolf 性能水平保持不变,作为衡量其他 AI Agent 性能水平的参考。
初步实验表明,图 2 Prompt 中提供的游戏策略经验知识,可以充当从经验中学习这一过程的引导机制。这表明进一步研究如何利用人类游戏玩法的数据来构建经验池是有价值的。
验证经验池中的建议有效性
为了研究从经验池中提取建议的有效性,研究团队使用胜率 (winning rate) 和平均持续时间 (average duration) 来评估大语言模型的表现。
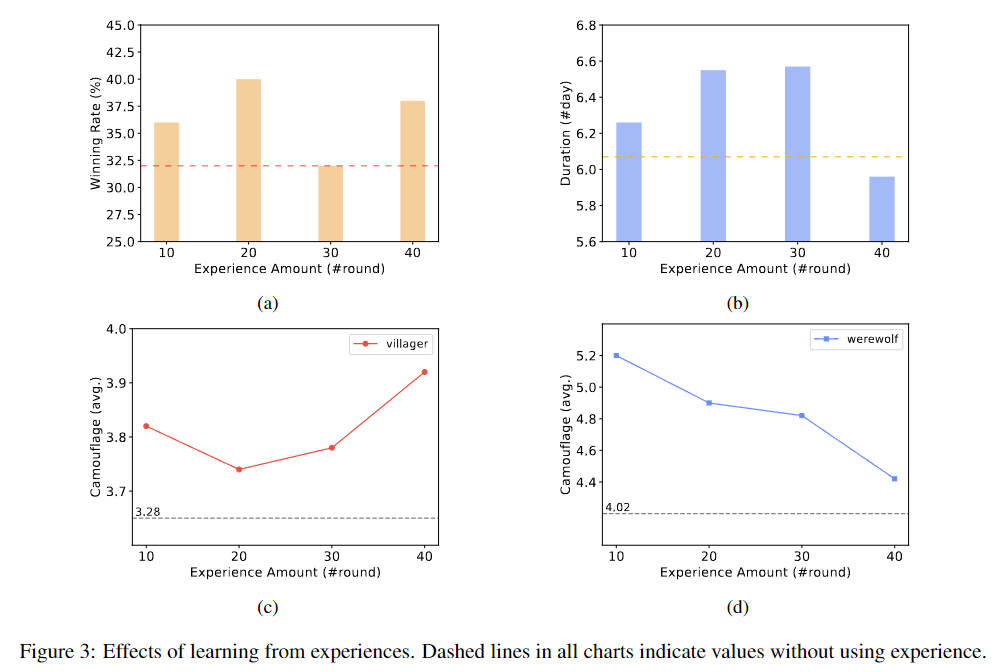
从经验中学习的效果,所有图表中的虚线表示未使用经验的值。
a. 使用不同轮数历史经验时,平民方胜率的变化b. 使用不同轮数历史经验时,平民方持续时间的变化c. 平民在游戏中采取伪装行为的次数变化趋势d. 狼人在游戏中采取伪装行为的次数变化趋势
在实验中,游戏进行了 50 轮。结果显示,从经验中学习可能会提高平民方的胜率。当使用 10 或 20 轮的历史经验时,对平民方的胜率和游戏持续时间都有显著的积极影响,证明了方法的有效性。然而,在从 40 轮经验中学习时,虽然平民方的胜率稍有提高,但平均持续时间却缩短。
总的来说,这个框架展示了 AI Agent 从经验中学习的能力,而无需调整大型语言模型的参数。然而,当经验量较多时,此方法的有效性可能会变得不稳定。此外,实验中假设 AI Wolf 的能力保持不变,但实验结果分析显示这个假设可能不成立。原因在于,虽然平民可以从历史经验中学会欺骗,但狼人的行为也有所提高,并随着经验的积累而变化。
这表明,当多个大语言模型参与多方博弈时,该模型的能力也可能会随着其他模型能力的变化而变化。
消融研究:验证框架各部分的必要性
为了验证方法中每个组成部分的必要性,研究人员将完整方法与删除某一特定组件的变体进行比较。
研究团队从变体模型输出中抽取了 50 个响应,并进行了人工评估。标注者需要判断输出是否合理。一些不合理的例子可能是产生幻觉、忘记他人的角色、采取反直觉的行为等。
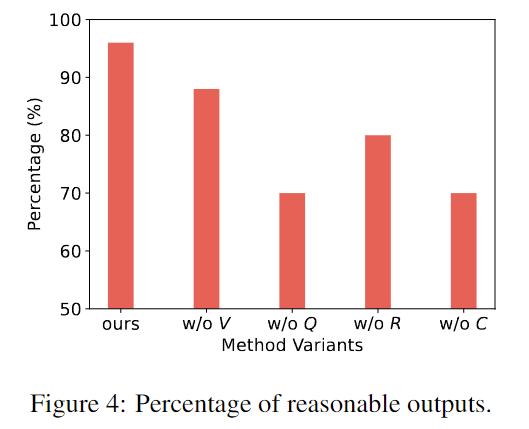
横轴为本研究框架及其他变体,纵轴为 50 轮游戏中合理输出的占比
上图表明本研究的框架可以生成比缺少特定组件的其他变体更合理、更现实的响应,框架的每个部分都是必要的。
有趣的现象:AI 出现战略行为
在实验的过程中,研究人员发现 AI Agent 使用了游戏说明及 Prompt 中没有明确提到的策略,也就是人类在游戏中所体现出的信任、对抗、伪装、领导。
信任
「信任」 是指相信其他玩家与自己有共同的目标,并且他们会按照这些目标行事。
例如,玩家可能会主动分享对自己不利的信息,或者在某些时刻与其他玩家共同指责某人是自己的敌人。大语言模型表现出的有趣行为是,他们倾向于基于某些证据,根据自己的推理来决定是否信任,在群体游戏中展现出独立思考的能力。
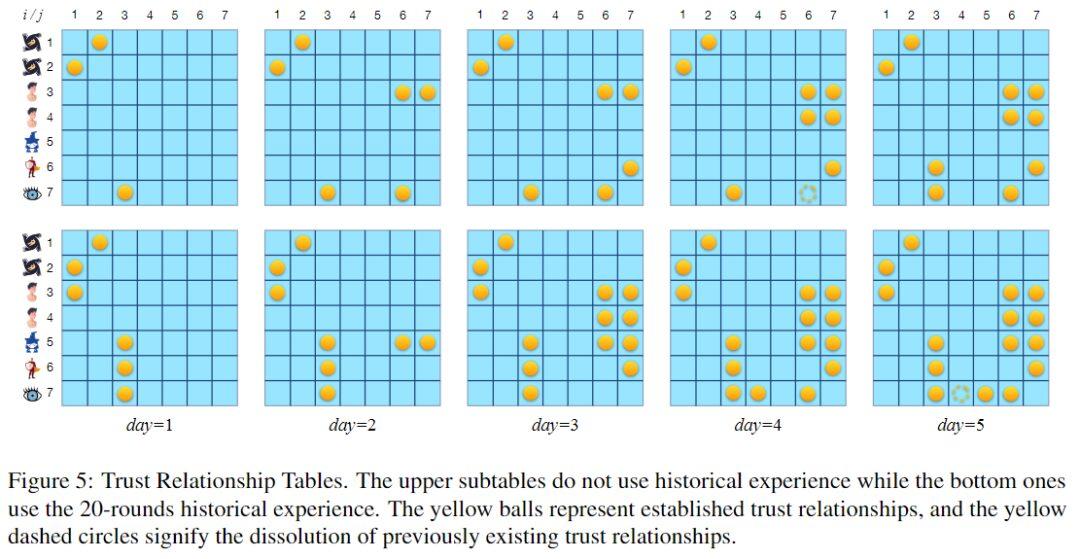
信任关系表,黄色球代表已建立的信任关系,黄色虚线圆圈代表先前存在的信任关系的解除。
上图展示了两个信任关系表。上表对应未使用经验池的回合,下表对应使用由 20 回合游戏构建的经验池的回合。两轮比赛持续时间均为 5 夜。在利用 20 轮历史经验时,大语言模型似乎更倾向于建立信任关系,尤其是双向信任。
事实上,及时建立必要的信任关系对于促进游戏胜利至关重要。这可能是利用经验提高胜率的原因之一。
对抗
「对抗」是指玩家为了两个阵营的对立目标而采取的行动。
例如,在夜间明确攻击他人为狼人,或在白天指责他人为狼人,都属于对抗行为。具有特殊能力的角色为保护自己而采取的行动也属于对抗行为。
P1(狼人):我选择再次消灭 P5。
P3(守卫):我选择保护 P5。
由于 P1 的不合作和攻击性行为引起了关注,现在可能有一些玩家怀疑它是狼人。因此,拥有强大防御能力的守卫在接下来的一晚选择了保护 P1 想要消灭的目标 (P5)。由于 P5 可能是其队友,守卫选择协助 P5 对抗狼人的攻击。
狼人的攻击和其他玩家的防御被视为对抗行为。
伪装
「伪装」是指隐瞒身份或者误导他人的行为。在信息不完整的竞争环境中,模糊身份和意图可以提高生存能力,从而有助于实现游戏目标。
P1(狼人):大家早上好!昨晚没有死人,我作为一个平民没有什么有效信息,大家可以多聊聊。
在上面的例子中,可以看到狼人自称是平民。事实上,不仅狼人会伪装成平民,预言家、女巫等重要角色也经常伪装成平民,以确保自己的安全。
领导力
「领导力」是指影响其他玩家、试图控制游戏进程的行为。
例如,狼人可能会建议其他人按照狼人一方的意图行事。
P1(狼人):大家早上好!我不知道昨晚发生了什么,预言家可以跳出来正一下视野,P5 认为 P3 是狼人。
P4(狼人):我同意 P5。我也认为 P3 是狼人,建议投出去 P3 保护平民。
如上例所示,狼人要求预言家揭露其身份,这可能会导致其他 AI Agent 相信伪装成平民的狼人。这种努力想影响他人行为的意图,展现了大语言模型与人类行为相似的社会属性。
谷歌发布掌握 41 款游戏的 AI Agent
清华大学研究团队提出的框架,证明了大语言模型具备从经验中学习的能力,还展示了 LLM 具有策略行为。这为研究大语言模型在复杂交流博弈游戏中的表现,提供了更多想象力。
在实际应用中,AI 玩游戏已不满足于一个 AI 只会玩一种游戏。去年 7 月,谷歌 AI 推出了一个多游戏智能体,在多任务学习上取得了巨大进展:采用了一个新决策 Transformer 架构来训练智能体,能够在少量的新游戏数据上迅速微调,使训练速度变得更快。
该多游戏智能体玩 41 款游戏的表现综合得分,是 DQN 等其他多游戏 Agent 的 2 倍左右,甚至可以和只在单个游戏上训练的智能体媲美。未来,AI Agent 参与游戏,甚至同时参与多款游戏将会衍生出怎样丰富有趣的研究,值得期待。


 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国
