
科研范式是常规科学所赖以运作的理论基础和实践规范,随着科学的发展以及外部环境的推动,人类的科学研究已经经历了经验科学、理论科学、计算科学以及数据科学四类范式。ChatGPT取得的瞩目成果展现了人机融合驱动的创新研究巨大潜力,可以看出,如今科研范式的变革正处在“哥白尼革命”的前夜,其基本理论和方法将会发生巨大变化。本文从ChatGPT的研发逻辑出发,分析了ChatGPT对科研范式变革的启示,对结合非线性抽象思维(人)和逻辑推理(机)的人机融合新科研范式进行了展望。
1. 科研范式总是随着科技的重大进步而变革
科学研究范式,指的是常规科学研究所赖以运作的理论基础和实践规范,是从事研究的科学家群体所共同遵从的世界观和行为方式[1]。科学研究范式建立的目的是帮助科学家们以最有效的方式完成科学研究,提高科学研究的准确性和可靠性。
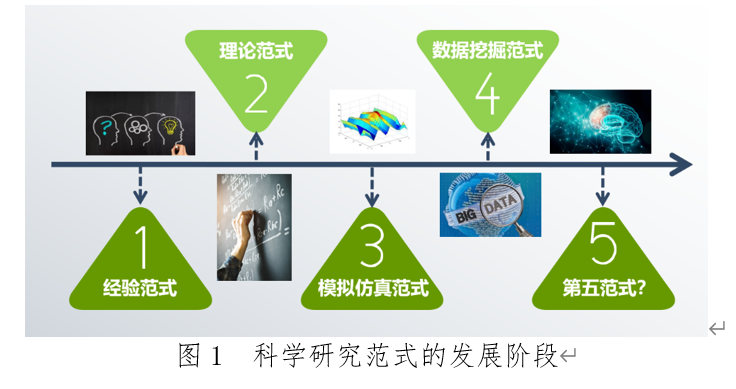
科学研究范式不是一成不变的,它会随着科学的发展以及外部环境的推动不断发生变化。由于科学家对科学研究范式的信奉,受到时代认知的局限性,某种科学研究范式总会在科学发展到一定程度后显示出不足而无法解决一些问题,出现困难、矛盾和困惑,这种矛盾推动了科学家们的反思和进一步探索,进而逐渐形成新的科学研究范式。美国科学哲学家Kuhn认为,科学家从一个旧范式跳到一个新范式时,往往是从一个预测性较弱的范式跳到一个预测性较强的范式,只不过他们在这样做的时候,根本无法理解新范式优越的预测力背后的根本原因[2]。根据图灵奖得主Jim Gray的观点,人类的科学研究已经经历了四类范式,分别是经验范式、理论范式、模拟仿真范式和数据挖掘范式[3]。科学研究范式的演进对于科学家理解和解决更复杂的科学研究问题发挥着重要指导性作用。
第一范式:经验范式:以经验主义和人的深度思考为主导的科学研究范式,实验是开展研究的主要手段。实验法最早可追踪到古希腊和中国,数千年文明史中,人类绝大多数技术发展源于对自然现象观察和实验总结。典型案例如:人类记录各种自然现象(钻木取火、摩擦起电等),柏拉图、亚里士多德对哲学的思考等。经验对于科学研究是必不可少的,但经验范式本质上是在已经猜测的理论之间进行选择,而不是发现理论[4]。

第二范式:理论科学:当实验条件不具备的时候,第一范式难以为继,此时为了研究更为精确的自然现象,催生出了新的科学研究范式。第二范式是以建模和归纳的理论学科和分析为主导的科学研究范式。相比于依赖观察和实验的第一范式可以做到“知其然”,第二范式的科学理论需要做到“知其所以然”,对自然界某些规律做出背后原理性的解释,不再局限于描述经验事实。如:数学中的集合论、图论、数论和概率论;物理学中的经典力学,相对论、弦理论、圈量子引力理论;地理学中的大陆漂移学说、板块构造学说;气象学中的全球暖化理论;经济学中的微观经济学、宏观经济学以及博弈论;计算机科学中的信息论等[4]。

第三范式:计算科学:随着理论研究的深入,以量子力学和相对论为代表的理论对超凡的头脑和复杂的计算提出了超高要求,同时验证理论的难度和经济投入也越来越大,第二范式面临重大瓶颈和挑战,迫切需要提出新的科学研究范式。第三范式是以计算和模拟为主导的科学研究范式,由1982年诺贝尔物理学奖获得者肯尼斯·威尔逊(Kenneth Wilson)提出并确立。20世纪后半叶,伴随高性能计算机和基于大规模并行计算的计算机体系结构的发展,科学家尝试在理论模型指导下,利用计算机设计数值求解算法、编写仿真程序来推演复杂理论、模拟复杂物理现象,如弹药爆炸、病毒传播、天气预报、人口增长、温室效应等。借助计算机的巨大算力,科学家可以精确地、大规模地求解方程组,进而去探索那些无法通过实验法和理论推导法解决的复杂问题。经过合理的模型假设和简化,第三范式主导的计算科学在经济学、心理学、认知科学等缺乏简单、直观分析解决方案的软科学问题中同样取得了成功应用。

第四范式:数据科学:第三范式是先提出可能的理论,再搜集数据进行仿真计算和验证,然而随着科学的发展和环境的变化,人们可能已经拥有了大量的数据,但难以直接提出可能的理论,此时第三范式的指导意义有限,需要开发或总结新的科学研究范式。第四范式是以数据驱动为主导,通过数据和算力探索前沿的科学研究范式,由1998年图灵奖获得者吉姆·格雷(JimGray)提出。第四范式以数据考察为基础,联合理论、实验和模拟等方法于一体,也称数据密集型科学[5]。其与第三范式的区别在于,随着数据量的高速增长,计算机不仅仅局限于按照科学家设定的程序规则开展模拟仿真,还能从海量数据中发现规律,形成基于关联关系的科学理论,其本质是通过海量数据的收集代替人类传统的经验观察过程,借助机器的高算力代替人类的归纳推理,从而实现远超经验范式的理论归纳能力。这种通过程序+数据发现规则的过程,可以在一定程度上代替过去由科学家才能完成的工作。当今处于数据爆炸的时代,数据科学成为技术发展的前沿领域,第四范式强调借助并行计算、数据挖掘、机器学习等技术去发现隐藏在数据中的关系与联系,将数据作为解决问题的工具而非问题本身。

2. ChatGPT正在接近人类研究问题的逻辑
2.1 ChatGPT/GPT4研发逻辑
ChatGPT是由OpenAI最新发布的一种对话式自然语言处理模型,其前身是InstructGPT模型[6],与BERT[7]等大语言模型(Large Language Model,LLM)相同,GPT采用了以Transformer[8]为核心的编码器-解码器结构。通俗来讲,该类模型的原理类似于人脑的语言处理过程,基于自注意力机制编码器能够获取文本内部的关联关系,进而将其编码为可存储、更抽象的语义向量。解码器则可根据该语义向量生成文本序列。鉴于自然语言任务的内在相似性,通过在海量文本数据上进行自监督训练,可以得到具有丰富知识表达的预训练模型,达到“理解”语言的目的,通过在机器翻译、知识问答等不同下游任务上进行微调训练,即可完成多种自然语言处理任务。
GPT第一代到第三代采用的都是监督学习的思路,但数据规模和模型规模爆炸式增长,GPT-1的参数量是1.17亿,预训练数据量约5GB,GPT-2分别使用了15亿参数和40GB的训练数据,而GPT-3的模型参数量多达1750亿,预训练数据量多达45TB[9],模型效果也明显提高,但是仍然存在内容胡编乱造、不遵循用户的明确指示、内容偏见有害等显著问题。
而ChatGPT的火爆,在于其文本生成结果的准确性、完整度、连贯性、交互性相较于GPT-3有了显著提升,在问答对话、代码生成、文本摘要等不同领域都接近甚至超过了人类水平。相对于GPT-3,ChatGPT核心创新点主要有三个方面。
2.1.1 指示学习(Instruct Learning)
大语言模型的主流训练模式经历了数次变迁。首先是预训练+微调(Pre-training + Fine-tuning),接着是提示学习(Prompt Learning)。但真正改变规则的是指示学习的前身——上下文学习(InContext Learning)。
OpenAI自GPT-2的研发中就开始探索大语言模型的泛化迁移(即零样本、小样本)能力,希望能够实现训练一个模型作为基座支撑,用户只需调用接口,输入想让其完成的任务要求即可,并不需要对大语言模型进行领域微调。但由于GPT-2仅抛弃微调阶段,其余基本延续GPT-1的两模式,其效果并不好。当到了GPT-3时,上下文学习被开创性的提出,部分解决了上述困境。与之前的训练模式相比,上下文学习在预训练阶段将输入样本组织成“任务描述+样例+提示”的模式,通过海量样本和1750亿训练参数的支撑,GPT-3基本实现了零样本能力。
OpenAI并未止步于此。在他们对人工智能的设想中,应该是人工智能优化改善人们的生活,而不是用户倒过来迁就它。上下文学习的确有效,但不符合人类的使用模式。日常中,非人工智能从业者们很难给出一个规范的“任务描述+样例+提示”,以要求人工智能给出答案。因此,OpenAI在ChatGPT的训练中继续往前走了一步,雇用了40名标注人员进行提示(Prompt)设计等工作[6],以人的认知经验引导模型的训练。在指示学习中,所有输入样例都符合真实应用场景中,人们的语言习惯和行文风格。比如执行翻译任务,训练样本大致上是“帮我把这个英文句子翻译成中文:Today is a good day”。通过这一设计,真正让人工智能服务于人类日常应用,并在最终性能表现上证明了其优异性。
2.1.2 人类反馈的强化学习(Reinforcement Learning with HumanFeedback,RLHF)
自Deepmind2017年研制出AlphaGo系列横扫围棋界后,强化学习破圈走进大众视野。但其在自然语言处理领域始终未能得到良好应用,根本原因之一在于目标难定义。不像棋类游戏那样有明确的规则约束,一段人工智能生成的文字或是给出的回答,很难直接判定“好坏”,这也就导致了强化学习中的奖励机制难以界定。
OpenAI在ChatGPT的实践中给出了一个精妙的设计思路,即人类反馈的强化学习。整个过程包含三个阶段。一是有监督学习阶段。先是通过专业标记者设计出小规模、高质量、全领域的提示语(Prompt),然后利用这些数据,微调GPT-3。二是奖励模型训练阶段。利用上一步获得的GPT-3,对收集到的真实问题生成系列答案,不同于以往给予生成文本固定奖励值的模式,OpenAI采用了答案排序机制:以是否符合人类认知作为标准对文本进行排序。让专业标记者对这些生成的答案进行排序,并用这些答案数据训练一个奖励模型。三是策略网络学习阶段。此处基于PPO的强化学习模式[10],针对输入的问题,让新模型(另一个GPT-3)生成答案,接下来通过前一步获得的奖励模型对答案打分,反馈更新策略网络。完成了强化学习的自训练迭代模式。
这一过程中最重要的创新点在于引入了人类的认知,答案不再是机器自己判断,或者少数专家给出“黄金解”(Ground Truth)。而是整合了用户的阅读习惯、言语风格等多方位的背景知识后,给出了相对合理的排序让机器去理解。
2.1.3 思维链(Chain of Thought,CoT)
思维链的技术通俗易懂,将以往期望模型能够一步学会的过程进行拆解,逐步输入到机器里。譬如计算一个复杂的数学逻辑题目,将计算过程分拆为一个个具体的步骤,指导模型一步步学习。
ChatGPT于2022年11月投入用户使用后,OpenAI不断对其在实践中暴露出的偏见、伦理、安全等方面的问题进行不断优化。但ChatGPT基座的GPT3.5模型本质上是仅能处理自然语言的单模态模型,未能将音视频、图像等多模态信息纳入其处理能力范畴。然而,随着2023年3月14日GPT4的发布,这些短板也被攻克。OpenAI总裁兼联合创始人格雷格·布罗克曼(Greg Brockman)表示:“GPT4不仅仅是一个语言模型,它还是视觉模型。”在官方演示视频中,格雷格用笔和纸画了个网站草图,拍照上传给GPT-4,让其自主编写一个网页,后者仅用1到2秒的时间,就生成了网页代码、制作出了几乎与图中一模一样的网站。
在具体性能方面,GPT4可接受的文字输入长度提升到了2.5万个单词,允许长内容创建、扩展对话以及文档搜索和分析等。可以更准确地解决高级推理难题,具有更广泛的常识和解决问题的能力,在专业和学术方面更是表现出接近于人类的水平。在模拟律师考试中,GPT4的得分能排进前10%左右,而GPT3.5的得分只能排在倒数10%左右。此外,GPT4不仅能对文本或图片进行单独的识别,还可以接受图文混排的内容。遗憾的是,OpenAI此次仅给出了98页关于GPT4的技术性能报告,未透露任何技术实现方面的细节。
2023年3月24日,OpenAI更是进一步宣布在ChatGPT中实现了对插件的初始支持,能够帮助ChatGPT访问最新信息、运行计算或使用第三方服务。此外,不仅亲自下场提供了两款插件:网络浏览器和代码解释器,还开源了知识库检索插件的代码,由任何开发人员自行托管。换句话说,OpenAI破除了ChatGPT能力边界的限制,通过第三方插件的形式,逐步打造新的AI生态圈,能够为人类衣食住以及工作、学习等方方面面提供更加优质的服务。
2.2 科研范式变革之前夜
复杂模型、海量数据、超大算力是当前科技的鲜明特征。据谷歌统计,自数字化时代以来全球产生的数据量基本服从“大数据摩尔定律”,即每两年就会翻一倍。尤其是近年来,随着一些复杂系统的出现,以及物联网技术的发展,人类社会积累的数据量呈加速增长趋势。例如,欧洲核子研究中心大型强子对撞机每秒钟就可以产生40兆兆字节的数据,一架波音喷气机引擎每分钟即产生20兆兆字节运行信息。国际数据公司(IDC)曾预测,全球数据总量将从2018年的33ZB(1ZB=10^21字节)增长到2025年的175ZB[11]。
通过超大算力对海量数据进行知识挖掘,通过人工智能技术实现复杂系统的推理,使得科学研究的效率得到了空前提高。在应用科学领域,李飞飞团队大型图数据库ImageNet[12]涵盖约2万类、1400万张标注了类别的图像,通过使用深度学习技术成功地提高了图像识别的准确率,将错误率降低到了历史最低水平;谷歌旗下DeepMind公司的AlphaZero[13]使用了深度学习和强化学习方法,在40天内进行了约4900万次围棋自我对弈,并达到了超越人类和其他计算机程序的水平。在基础科学领域,DeepMind使用人工智能来帮助证明或提出新的数学定理,辅助数学家形成对复杂数学的直觉;AlphaFold基于生命科学积累的大量数据,能在几分钟内预测出一个典型蛋白质的结构,无需对蛋白质进行结晶或使用昂贵的冷冻电镜进行研究,颠覆了传统结构生物学的研究模式。在分子生物学、天文学、地理科学、大气科学等数据积累丰富、结构化程度高、问题定义清晰的领域,数据和人工智能的结合已经带来了科研范式的巨大变革。
当前,科学研究正在进入人机融合的时代,ChatGPT采用人机融合的设计模式。借助人类反馈的强化学习技术实现了对话这一自然语言处理任务的突破,2023年3月14日发布的GPT-4模型[14],拥有图像识别、高级推理等功能,其单词处理能力是GhatGPT的8倍,在模拟律师考试、SAT(美国高考)数学考试中成绩分别超过90%和89%人类考生,可见,在具有主观、非线性、不良结构特征的研究对象上,仅靠机器已经难以实现有效的科学发现,基于人机融合的科学研究方式开始展现其强大的潜力。
近年来,大数据、人工智能等相关技术的更新换代呈现出越来越快的趋势。以自然语言处理(NLP)领域为例,其自诞生之日起历经五次研究范式转变,其中小规模专家知识方法发展了40年(1950-1990),浅层机器学习模型发展了20年(1990-2010),深度学习算法发展历时10年(2010-2017),而大语言模型从2018年概念提出到ChatGPT产品落地才用了5年。新一代技术何时出现不得而知,但也许,我们已经到了科研范式发生变革的前夜。
3. 人机融合的科研第五范式渐露端倪
随着数据获取以及计算能力的不断提高,科学研究从经验范式发展到了数据科学范式,可以从海量数据中挖掘出仅凭人脑难以发现或总结的科学规律,但经过多年的科学实践可以发现,不论是计算科学还是数据科学范式,在面对社会、经济、人脑智能等复杂巨系统科研对象时,都存在数理模型难以构建、数据学习效率低下、内在机理不明等局限性,数据科学范式的主要作用是发现关联规律,而忽略了因果关系,而很多情况下,简单的因果推断就能胜过大量数据分析所得到的经验规律[16],如果仅靠数据的统计分析,不赋予机器常识和深度理解能力,则很难在复杂对象的科学理论发现上达到人类的智能水平[17][18]。GPT1到GPT3等ChatGPT的前代版本通过典型的数据科学范式进行设计,虽然在很多自然语言处理任务上取得了较好的效果,但难以实现类人响应,ChatGPT进行了颠覆式迭代,通过将人类经验融合到模型设计当中,使其具备了从人类的反馈中强化学习并重新思考的能力,在对话这一自然语言处理任务上实现了突破性的效果。
可以看出,通过将人的直觉性经验或专家性经验融合到数据模型或者计算模型当中,以人类专家经验引导改进“机器”的低效探索,发挥“机器”的计算能力优势和人类的直觉性优势,以人机融合、人在回路的形式进行科学实践,可以弥补“机器”无法感知或推理某些难以量化的科学规律上的局限性。随着研究对象从客观对象向主观对象不断发展、从简单系统向复杂巨系统不断拓展,科学研究的范式也正在从数据科学范式向人机融合的第五范式转变。
在已有的四个科研范式中,科技进步为人们提供了新的理论、方法和工具,但人类始终没有被作为生产力列入科研范式之中。事实上,人在科研范式中的主导地位一直存在,例如第一范式中人类观察总结,第二范式中人类归纳推导,第三范式中人类建模分析,第四范式中人类设计框架等。人在科研范式中的主导地位是因为人类具有非线性抽象思维,人的大脑是开放变化的复杂系统,能够轻松实现整体大于部分之和;善于处理关联演化性问题,哪怕对于无迹可寻的事物也可能顿悟致知。科研范式发展到今天,借鉴ChatGPT的研发逻辑,人的定位应该从幕后走向台前,为擅长逻辑推理的机器赋予人类特有的非线性抽象思维,机器积累量变,人脑触发质变,螺旋升级共同促进科学技术的进步和发展,实现真正意义上的人机融合,称之为科研第五范式。
人机融合的科研第五范式可简要概述如下:首先,人类深度参与、促进并主导机器进化,创造更加开放、更加智能、更加强大的工具;其次,新工具将人类从一部分“体力”劳动中解放出来,让人集中精力于非线性抽象思维,同时新工具还可能提高人类的整体认知水平,为人脑进化创造新环境;然后,认知或思维进化后的人类再次/同时促进擅长逻辑推理的机器进化,如此迭代,相互纠缠,螺旋上升。

- 总结
如美国著名哲学科学家Thomas Samuel Kuhn所述,科研范式是常规科学所赖以运作的理论基础和实践规范。ChatGPT的横空出世,让我们看到,如今科研范式的变革正处在“哥白尼革命”的前夜,其基本理论和方法将会发生巨大变化。如同牛顿引力理论取代亚里士多德物体运动理论,相对论和量子物理取代引力理论,达尔文进化论取代神创论。在经历经验科学范式(直观描述现象)、理论科学范式(基于模型或归纳表征现象)、计算科学范式(仿真模拟复杂现象)、大数据科学范式(数据分析挖掘)之后,我们相信以逻辑推理(机)结合非线性抽象思维(人)的人机融合新科研范式无疑将会大放异彩,它更加强调创新导向、价值导向、贡献导向;更有利于推动科研模式从无价值负载的信马由缰式研究转向负责任、有组织的研究转变,更能够促进如曼哈顿工程、阿波罗登月计划、引力波探测、中国的神舟飞船等大科学、大工程的建设,在未来科学技术发展中占据主流位置,成为推动科技发展的重要基础。
* 转载请注明:周刚,王锐,李凯文,宋国鹏,黄生俊,刘天宇,廖劲智,刘威,“觉悟ChatGPT,科研第五范式即将来临”,2023年04月04日。
* 联系人:王锐,国防科技大学系统工程学院,湖南省长沙市开福区德雅路109号,邮箱:szxtgc_nudt@163.com 。
* 本文首发于中国仿真学会公众号,2023/4/4。
参考文献:
[1]Tansley S, Tolle K M. The fourth paradigm: data-intensivescientific discovery[M]. Redmond, WA: Microsoft research, 2009.
[2]Kuhn T S. The structure of scientific revolutions[M].University of Chicago press, 2012.
[3]Hey T, Trefethen A. The fourth paradigm 10 years on[J].Informatik Spektrum, 2020, 42: 441-447.
[4][英]戴维·多伊奇. 无穷的开始:世界进步的本源(第2版)[M].人民邮电出版社, 2019.
[5]Bell G, Hey T, Szalay A. Beyond the data deluge[J]. Science,2009, 323(5919): 1297-1298.
[6]黄欣卓, 米加宁, 章昌平, 等. 科学数据复用研究的演化, 知识体系与方法工具——兼论第四科研范式的影响[J]. 科研管理, 2022, 43(8): 100.
[7]Ouyang L, Wu J, Jiang X, et al. Training language models tofollow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155,2022.
[8]Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deepbidirectional transformers for language understanding[J]. arXiv preprintarXiv:1810.04805, 2018.
[9]Vaswani A, Shazeer N, Parmar N, et al. Attention is all youneed[J]. Advances in neural information processing systems, 2017, 30.
[10] Brown T, Mann B, Ryder N, et al. Language models are few-shotlearners[J]. Advances in neural information processing systems, 2020, 33:1877-1901.
[11] Schulman J, Wolski F, Dhariwal P, et al. Proximal policyoptimization algorithms[J]. arXiv preprint arXiv:1707.06347, 2017.
[12] Reinsel D, Gantz J, Rydning J. The digitization of the worldfrom edge to core[J]. IDC white paper, 2018, 13.
[13] Deng J, Dong W, Socher R, et al. Imagenet: A large-scalehierarchical image database[C]//2009 IEEE conference on computer vision andpattern recognition. Ieee, 2009: 248-255.
[14] Silver D, Hubert T, Schrittwieser J, et al. A generalreinforcement learning algorithm that masters chess, shogi, and Go throughself-play[J]. Science, 2018, 362(6419): 1140-1144.
[15] OpenAI. GPT-4 Technical Report[R]. arXiv preprint arXiv:2303.08774, 2023.
[16] Pearl J, Mackenzie D. The book of why: the new science ofcause and effect[M]. Basic books, 2018.
[17] Mitchell M. Artificial intelligence: A guide for thinkinghumans[M]. Penguin UK, 2019.
[18] Marcus G, Davis E. Rebooting AI: Building artificialintelligence we can trust[M]. Vintage, 2019.



 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国
