

复刻(英语:fork,又译作派生、分支)是UNIX或类UNIX中的分叉函数,fork函数将运行着的程序分成2个(几乎)完全一样的进程,每个进程都启动一个从代码的同一位置开始执行的线程。这两个进程中的线程继续执行,就像是两个用户同时启动了该应用程序的两个副本。
从一个软件包拷贝了一份源代码然后在其上进行独立的开发,创建不同的软件。这个术语不只意味着版本控制上的分支,同时也意味着开发者社区的分割,是一种形式的分裂。
自由及开放源代码软件可以从原有开发团队复刻而不需要事先的许可,这也不会违反任何著作权法律。授权的专有软件(例如Unix)的复刻也时有发生。
介绍fork系统调用用于创建一个新进程,称为子进程,它与进程(称为系统调用fork的进程)同时运行,此进程称为父进程。创建新的子进程后,两个进程将执行fork()系统调用之后的下一条指令。子进程使用相同的pc(程序计数器),相同的CPU寄存器,在父进程中使用的相同打开文件。
它不需要参数并返回一个整数值。下面是fork()返回的不同值。
负值:创建子进程失败。
零:返回到新创建的子进程。
正值:返回父母或来电者。该值包含新创建的子进程的进程ID1。
分叉函数头文件
#include/*#包含*/#include/*#包含*/函数原型pid_t fork( void);
(pid_t 是一个宏定义,其实质是int 被定义在#include中)
返回值: 若成功调用一次则返回两个值,子进程返回0,父进程返回子进程ID;否则,出错返回-1
函数说明一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程(child process)。fork函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。
子进程是父进程的副本,它将获得父进程数据空间、堆、栈等资源的副本。注意,子进程持有的是上述存储空间的“副本”,这意味着父子进程间不共享这些存储空间。
UNIX将复制父进程的地址空间内容给子进程,因此,子进程有了独立的地址空间。在不同的UNIX (Like)系统下,我们无法确定fork之后是子进程先运行还是父进程先运行,这依赖于系统的实现。所以在移植代码的时候我们不应该对此作出任何的假设。
为什么fork会返回两次?
由于在复制时复制了父进程的堆栈段,所以两个进程都停留在fork函数中,等待返回。因此fork函数会返回两次,一次是在父进程中返回,另一次是在子进程中返回,这两次的返回值是不一样的。过程如下图。
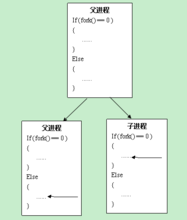
fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值:
(1)在父进程中,fork返回新创建子进程的进程ID;
(2)在子进程中,fork返回0;
(3)如果出现错误,fork返回一个负值。
在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
引用一位网友的话来解释fork函数返回的值为什么在父子进程中不同。“其实就相当于链表,进程形成了链表,父进程的fork函数返回的值指向子进程的进程id, 因为子进程没有子进程,所以其fork函数返回的值为0.
调用fork之后,数据、堆、栈有两份,代码仍然为一份但是这个代码段成为两个进程的共享代码段都从fork函数中返回,箭头表示各自的执行处。当父子进程有一个想要修改数据或者堆栈时,两个进程真正分裂。
示例代码:
#include#include#includeint main(int argc,char *argv[]){ pid_t pid=fork(); if ( pid

 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国