

简介
为了让用户从大量信息中找到自己感兴趣的信息,推荐系统已逐渐成为电子商务中一个必不可少的工具,并且得到研究者的关注。协同过滤推荐系统是目前为止成功、且运用最多的推荐技术,与传统的直接分析内容进行推荐不同,基于用户的协同过滤推荐系统通过分析用户兴趣,在用户群中找到与指定用户的相似用户,综合户对该项目的喜好程度。1
为找这些相似用户对同一项目的评价,预测出该用到目标用户的最近邻居进行推荐,必须度量用户之间的相似性,然后选择相似性最高的若干用户,作为目标用户的最近邻居。目标用户的最近邻居查询是否准确,直接关系到整个推荐系统的推荐质量,而要想准确查询目标用户,需要准确计算不同用户之间的相似性,所以如何准确计算用户之间相似性就成为提高推荐准确率的关键。计算用户之间相似性的方法主要包括余弦相似性,修正的余弦相似性以及相关相似性等。
相似性度量
相似性度量,即综合评定两个事物之间相近程度的一种度量。两个事物越接近,它们的相似性度量也就越大,而两个事物越疏远,它们的相似性度量也就越小。相似性度量的给法种类繁多,一般根据实际问题进行选用。常用的相似性度是有:相关系数(衡量变量之间接近程度),相似系数(衡量样品之间接近程度),若样品给出的是定性数据,这时衡量样品之间接近程度,可用样本的匹配系数、一致度等。2
用数量化方法对事物进行分类,就必须用数量化方法描述事物间的相似程度。一个事物常常需要用多个变量来刻画,如对一群用p个变量描述的样本点进行分类,则每个样本点可看做是p维空间的一个点,很自然的想到用距离来度量样本点间的相似程度。
相似性度量方法
协同过滤推荐技术中一个必不可少的步骤是计算目标用户与其他用户之间的相似性,从而生成最近邻居集合,进而产生推荐,传统的相似性计算方法有以下3种。1
余弦相似性
用向量和分别表示用户i 和用户j 的评分向量,而它们的相似性就是通过计算向量之间夹角的余弦来进行度量,则用户x 和用户y 之间的相似性为
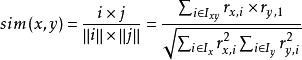
修正余弦相似性
考虑到用户之间评分尺度的不同,公式中利用用户的平均评分作出了一定的修正,即用户i 和用户j 之间的相似性。
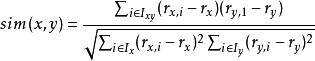
相关相似性
用户之间的相似性通过计算两个用户评分向量之间的线性关系来进行衡量,则用户i 和用户j 之间的相似性
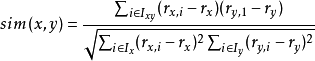
余弦相似性度量方法把用户评分看作一个向量,用向量的余弦夹角来度量用户间的相似性,然而没有包含用户评分的统计特征;修正的余弦相似性方法在余弦相似性的基础上,减去了用户对项目的平均评分,该方法更多地体现了用户间的相关性而非相似性;相关相似性方法依据双方共同评分的项目进行用户相似评价,能够更好地体现用户的相似程度,但相关相似性在计算用户之间相似性上还存在着一些问题。
相关相似性缺点
下面通过具体事例说明相关相似性存在的问题:2
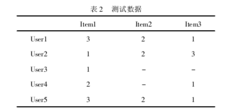
(1)未考虑用户评分项的数量对相似度的影响。
表1中,行与列的交叉点表示用户(1 ~5)对项目(1~3)的一些评分值。直观来看,User1和User5用3个共同的评分项,并且给出的评分趋势相同,User1与User4只有2个相同评分项,虽然他们的趋势也相似,但由于User4对Item2的评分未知,可能是User4对Item2未发生行为,或者对Item2很讨厌,所以更希望User1和Users更相似,但结果是 Userl与User4有着更高的结果。可以看出相关相似性只会对共同评价过的记录进行计算。
同样的场景在现实生活中也经常发生,例如用户A和用户B各观看了200部电影,用户C只看了2部电影,而用户A和B共同观看的200部电影完全相同,虽然不一定给出相同或完全相近的评分,但只要他们之间的趋势相似也应该比另一位用户C只观看了2部相同电影的相似度高。但事实并非如此,如果对这两部电影,两个用户给出的相似度相同或很相近,通过相关相关性计算出的相似度会明显大于观看了相同的200部电影的用户之间的相似度;
(2)只有一个共同评分项则无法计算相关性。由公式可以看出,若两用户之间只有一个共同的评分记录或无共同评分记录,那么将导致分母为0,从这一点也可以看出,相关相似性不适用于冷启动问题。但是,这一特性也有它的好处,当无法计算相关相似性可以认为这两个用户之间没有任何相关性,即他们之间的相似性为零。
相似性计算方法正态分布函数
正态分布是一个在数学、物理及工程等领域都非常重要的概率分布函数。1
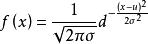
通过式可以看出,当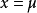 时f(x)达到最大值,而当
时f(x)达到最大值,而当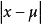 的值越大,
的值越大,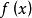 的值越小。
的值越小。
修正函数
将在正态分布函数的基础上,设用户x 的评分项目个数为m,用户y的评分项目个数为n,max(m,n)表示用户,和用户y评分项目集合中评分项目个数较大的项目数,令正态分布函数中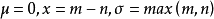 ,经过变换得到函数
,经过变换得到函数
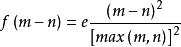
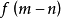 易知,当m=n时,取得最大值为1,当
易知,当m=n时,取得最大值为1,当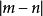 越大,的值越小随着不断增加,
越大,的值越小随着不断增加,
逐渐从1趋近于0,且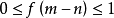 。
。
改进后的相似性计算方法
正是由于相关相似性没有考虑用户评分记录项的数量对相似度的影响,而导致了两用户A和C观看了相同2部电影的相似度会明显大于观看了相同200部电影的用户A和B之间的相似度。故可以在相关相似性的基础上添加一个修正函数来修正两用户之间由评分项目数量差距带来的负面影响,即
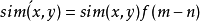
在前面例子的基础上,由于用户A和用户B有过的评分电影完全相同,则用户A和用户B之间的修正函数为: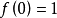 ;而用户A和用户C有过的评分电影只有两部,且二者观看电影数量差距较大,则用户A和用户C之间的修正函数为f(198) =0.376。
;而用户A和用户C有过的评分电影只有两部,且二者观看电影数量差距较大,则用户A和用户C之间的修正函数为f(198) =0.376。
假设有5个用户User5~User5,且他们的评分项目数为200,100,70,30和10,则他们之间的惩罚函数值如表2所示。
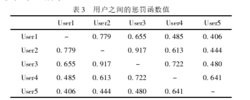
表2中行与列的交叉点为两用户的修正函数数值,易知:当两用户的评分项目数差距越大时,修正函数对其相关相似性的修正力度也就越大,这正好符合文中的预期。1
 扫码下载APP
扫码下载APP
 科普中国APP
科普中国APP
 科普中国
科普中国
 科普中国
科普中国